見出し一覧
基本的に時系列順なので副題が前後しているが容赦していただきたい。
- 序: 褪色画像と復元標本
- 前準備 [その1]: 機械学習(人工ニューラルネットワーク)
- 前準備 [その2]: 動画の読み込み
- 機械学習による褪色復元
- 動画の出力
- 中間ニューロン数の調整
- 別の標本を用いた訓練
- まとめみたいな何か
- 付録
序: 褪色画像と復元標本
C#の話の前に前書きを。
褪色とは何ぞや
日に当たったり時間経過したりで写真等が色褪せること。「退色」も「褪色」も意味は同じらしい。
最終目標
この動画を綺麗に復元したい。画質はともかくとして色だけでも綺麗にしたい。
-
ぼくらの特急 パノラマカー
http://www.nicovideo.jp/watch/sm3808175
数年前に放映していたCMではこのPR映画の一部場面が使われていたので名古屋圏の人は見たことがあるかもしれない。
そのCMを見ていればわかるのだが、本来はもっと高画質で色鮮やかな映像が存在する。
残念ながら全編は一般には出回っていないようで、一応探しては見たものの出てこなかった。
実は鉄道ファン向けの「鉄道伝説 Blu-ray第2巻」に得点映像としてこのPR映画が(恐らく)全編入っている。
しかし以下のサンプルを見るに画質はかなり悪い。
音声はノイズが軽減されており映像も細部は多少マシに見えなくもないが、ぶっちゃけ画質・色彩ともニコニコにあるやつと同レベル。
BSフジは日車か名鉄に頼み込んでちゃんとした映像をもらってくるべき。ガッカリ画質すぎる。
-
鉄道伝説 Blu-ray第2巻 特典映像 僕らの特急 - YouTube
https://www.youtube.com/watch?v=snR-qDFGEf4
何だかんだ言ってこの映像は東京オリンピックより前(1961年っぽい)のカラー映像、それも原本時点では映画画質という貴重映像。
沿線の観光案内なども入っており、全編が綺麗な映像で見られたらそれなりに嬉しい。せめて色だけでも鮮やかにしてみたい。
幸いなことにこの映像の復元にはいくらかの標本があるので、色はこれに近づけることで全編に亘り鮮やかさを復元してみたい。
ちなみに以下のDVDにはこの記録映画の一部が高画質で入っているが、ひとまずはCMの映像のみを標本として用いる。
-
S138 DVD 「名鉄7000系パノラマカー」 2枚組 まさに車両メーカーである日本車両の「日車夢工房」ならではの企画です。貴重な映像をお楽しみ下さい。
http://www.eki-net.biz/yumekobo/g38920/
まずは既存の手段でどうにかならないか試してみる。とりあえずキャプを撮ってGIMPで色を補正してみる。
以下が標本の一部。CMの一場面を切り出したものだが、あくまで検証用なので悪しからず。
 画像00: 標本画像
画像00: 標本画像
50年以上前の映像とは思えない綺麗さである。標本としては申し分なさそうだ。
「♪小田和正」の部分は標本としては使えないので除外するようにしなければならない。因みに曲は「緑の街」。
そして以下がニコニコから取ってきた動画の補正前キャプチャ。かなり画質が悪い。
 画像01: 動画の補正前キャプチャ
画像01: 動画の補正前キャプチャ
でもって以下がGIMPによる補正後。多少はマシになってくれたようだが素人にはこれが限界。
 画像02: キャプチャ画像の補正結果
画像02: キャプチャ画像の補正結果
カラーバランス・色相等をゴニョゴニョしてここまで来たが、手応えはイマイチといったところ。
原本映画が綺麗すぎるというのもあるが、満足のいく結果かというと微妙と言わざるを得ない。
専門家じゃないのでヒストグラムとか色相とか彩度とかそういう細かい調整を手作業で行うことは諦める。
代わりに、その辺りのあらゆる調整項目を機械学習というブラックボックスに任せてしまおうと相成った。
前準備 [その1]: 機械学習(人工ニューラルネットワーク)
機械学習といってもいろいろある。が、自分で1から実装するのは無理がありそう。
-
機械学習を知識ゼロから学ぶpdf - NAVER まとめ
http://matome.naver.jp/odai/2137978900585239401 -
機械学習 - Wikipedia
http://ja.wikipedia.org/wiki/機械学習
そこで今回も既存ライブラリのお世話になる。画像処理で使ったOpenCVだが実は機械学習もできてしまう優れものだったりする。
OpenCvSharpからも使えるようなので早速試してみる。
-
OpenCvSharpをつかう その16(SVM) - schima.hatenablog.com
http://schima.hatenablog.com/entry/2013/11/10/235351
上の例ではサポートベクターマシン(SVM)という計算技法を使っている。
これは入力データを2種類の集合のどちらに分類するべきかを学習して未知の入力に対する出力を予測するアルゴリズムらしい。
しかし今回行いたいのは復元前の色情報から復元後の色情報へのマッピングなので、この技法そのままでは駄目。
色情報はRGBの3次元データとして扱うので、3次元の入力に対して3次元の出力が得られなければならない。
そこで今回はニューラルネットワーク(Neural Network, NN)という計算技法を用いる。詳細は以下を参照。
-
opencv.jp - OpenCV-1.0:機械学習 ニューラルネットワーク(Neural Networks)リファレンス マニュアル -
http://opencv.jp/opencv-1.0.0/document/opencvref_ml_nn.html#ch_ann -
ニューラルネットワーク — opencv 2.2 documentation
http://opencv.jp/opencv-2svn/cpp/ml_neural_networks.html -
opencvsharp/CvANN_MLP.cs at master · shimat/opencvsharp · GitHub
https://github.com/shimat/opencvsharp/blob/master/src/OpenCvSharp.CPlusPlus/modules/ml/CvANN_MLP.cs -
パーセプトロン - Wikipedia
http://ja.wikipedia.org/wiki/パーセプトロン#.E5.A4.9A.E5.B1.A4.E3.83.91.E3.83.BC.E3.82.BB.E3.83.97.E3.83.88.E3.83.AD.E3.83.B3
ANNは人工ニューラルネットワーク(Artificial NN)の略、MLPは多層パーセプトロン(Multilayer perceptron)の略。
ざっくりと言ってしまえば、入力と出力の間に複雑なネットワークが構築されるのでかなり複雑な予測もできる、という代物らしい。
OpenCvSharpからCvANN_MLPを使う
OpenCvSharpからのMLP使用例が見当たらなかったのでSVMの使用例を参考にテスト用のコードを書いてみた。
CvPoint3D64f[] points = new CvPoint3D64f[500];
CvPoint3D64f[] responses = new CvPoint3D64f[500];
Random rand = new Random();
for (int i = 0; i < points.Length; i++)
{
points[i] = new CvPoint3D64f(rand.Next(0, 255), rand.Next(0, 255), rand.Next(0, 255));
responses[i] = new CvPoint3D64f(
points[i].X / 2 + points[i].Y / 2,
points[i].X / 3 + points[i].Y / 3 + points[i].Z / 3,
points[i].Z / 4
);
}
CvMat dataMat = new CvMat(points.Length, 3, MatrixType.F64C1, points, true);
CvMat resMat = new CvMat(responses.Length, 3, MatrixType.F64C1, responses, true);
CvANN_MLP mlp = new CvANN_MLP();
CvMat layerSizes = new CvMat(1, 3, MatrixType.S32C1, new int[3] { 3, 7, 3 }, true);
mlp.Create(layerSizes);
mlp.Train(dataMat, resMat, null);
CvMat sampleMat = new CvMat(1, 3, MatrixType.F64C1, new double[3] { 200, 150, 100 });
CvMat sampleMatOut = new CvMat(1, 3, MatrixType.F64C1, new double[3]);
mlp.Predict(sampleMat, sampleMatOut);
Debug.WriteLine(sampleMatOut);
何をしているか一応説明。まず3次元のデータを適当に500個作ってそれを入力の標本とする。
入力標本の座標について、「XとYの平均」・「XとYとZの平均」・「Z/4」をそれぞれ新たな座標とするような3次元データを新たに作る。
これを各入力に対応する出力の標本とする。こうして作った3次元データ500組をMLPに突っ込んで入出力の相関関係を学習させる。
試したところSVMの例とは異なりデータの正規化は必要ないらしいので、座標値は0~255の範囲で割り当ててある。
あとSVMと異なるのはmlp.Create()で予めトポロジーを指定しないといけない。でないとエラーを吐いて止まってしまう。
トポロジーといってもニューラルネットワークのネットワークトポロジーは入力層・中間層・出力層のニューロン数だけで決まる。
学習し終えたところで問い合わせ用のデータとして{ 200, 150, 100 }を用意。
学習データは毎回適当に作っているので、同じ問い合わせに対して実行ごとに毎回異なる結果が返ってくる。
今回得られた出力は{ 176.995613915879, 151.252219093907, 23.6799880314829 }であった。
期待される出力は{ 175, 150, 25 }なので、かなりの精度といえるだろう。
今度はこんな風に書き換えてみる。
CvPoint3D64f[] points = new CvPoint3D64f[2500];
CvPoint3D64f[] responses = new CvPoint3D64f[2500];
Random rand = new Random();
for (int i = 0; i < points.Length; i++)
{
points[i] = new CvPoint3D64f(rand.Next(0, 255), rand.Next(0, 255), rand.Next(0, 255));
double y = (points[i].X * 0.298912) + (points[i].Y * 0.586611) + (points[i].Z * 0.114478);
responses[i] = new CvPoint3D64f(y, y, y);
}
見てもらえれば分かるがRGBを輝度に変換してグレースケールに変換する操作をシミュレートしている。
2500色のグレースケール化サンプルから、残りの16,774,716色(256^3-2500色)がどうグレースケール化されるか予測してもらう。
今回も問い合わせに同じデータを用いたところ出力は{ 163.765218467695, 158.236959850528, 155.60028854036 }であった。
期待される出力は{ 159.22185, 159.22185, 159.22185 }なので、まあまあといったところ。
グレースケール化の標本は全色の0.0149%(1万分の1.5)程度しか与えていないことを考えれば上等といえるだろう。
学習情報の保存・読み出し
ソフトを終了した瞬間に学習したデータが吹っ飛ぶのではあまり意味がないので、学習データを保存して後で読み出せるようにする。
これもOpenCvSharpで実装した例が見つからなかったので以下を参考にした。
-
Is there a way to save and restore trained neural network weights? - OpenCV Q&A Forum
http://answers.opencv.org/question/16096/is-there-a-way-to-save-and-restore-trained-neural-network-weights/ -
ご注文は機械学習ですか? - kivantium活動日記
http://kivantium.hateblo.jp/entry/2014/11/25/230658 -
opencvsharp/CvFileStorage.cs at master · shimat/opencvsharp · GitHub
https://github.com/shimat/opencvsharp/blob/master/src/OpenCvSharp/Src/Class/CvFileStorage.cs
それで適当に書いてみた。学習データの保存は以下のような感じ。
using (CvFileStorage fs = new CvFileStorage("mlp.xml", null, FileStorageMode.Write))
{
mlp.Write(fs, "mlp");
}
問い合わせに対するこの時の学習データによる応答は{ 170.169544211544, 164.018921967788, 160.185936004012 }であった。
フォルダを覗いてみるときちんと"mlp.xml"が出力されていた。このファイルの大きさは3.01KBと思ったより小さめ。
今度は逆に読み込んでみる。標本データを突っ込んで訓練させる代わりに以下を挿入する。
using (CvFileStorage fs = new CvFileStorage("mlp.xml", null, FileStorageMode.Read))
{
CvFileNode fn = fs.GetFileNodeByName(null, "mlp");
mlp.Read(fs, fn);
}
このようにしてxmlから読み込んだ学習データによる応答は先程と同じ{ 170.169544211544, 164.018921967788, 160.185936004012 }であった。
コードは適当だけどとりあえず動いたのでおk。xml読込はGCを信じて以下のように書いてもよい(はず)。
mlp.Load("mlp.xml","mlp");
何にせよ、これで学習した記録をそのまま残せるようになった。
皆さんも上に書いたやつを適当にコピペすれば機械学習できちゃうので是非。知識の共有大事。
前準備 [その2]: 動画の読み込み
動画の処理といえばFFmpegのようなエンコーダやDirectShowを介して行うのが定番。
でも今回はWindowsのFormに動画フレームを表示したいのでまたまたOpenCVに頑張ってもらう。
OpenCV+OpenCvSharpで動画を読み込むにはどうするか調べた(といってもググっただけ)ら以下のような記事たちが出てきた。
-
OpenCvSharpをつかう その7 (WindowsFormsで動画の再生) - schima.hatenablog.com
http://schima.hatenablog.com/entry/20090925/1253852774 -
OpenCvSharpで動画再生 - SourceChord
http://sourcechord.hatenablog.com/entry/2014/10/05/022144 -
OpenCVで動画入出力をしてみただけ - とあるPGの研究記録Ⅱ(レコーダー)
http://nullorempry.jimdo.com/2012/09/28/opencv/
つまり、OpenCVが裏でFFmpeg使って1フレームずつ取り出してくれるのでそれをpictureBoxに描画しまくる、ということらしい。
素人目には何とも怪しげな挙動に思われてならないが、メモリ関係も上手く処理できる方法があるっぽいので気にせず実装。
まずはその辺は気にせずにBackgroundWorkerでお手軽実装。GCを信じてコードを書く。
FFmpegで読めれば動画は何でもいいのでflvだろうがmp4だろうが気にせず突っ込むことができる。基本は以下の通り。
private void backgroundWorker1_DoWork(object sender, DoWorkEventArgs e)
{
BackgroundWorker bw = (BackgroundWorker)sender;
using (CvCapture capture = new CvCapture("sm3808175_.flv"))
{
int interval = (int)(1000 / capture.Fps);
IplImage image;
while ((image = capture.QueryFrame()) != null)
{
bw.ReportProgress(0, image);
if (bw.CancellationPending)
{
e.Cancel = true;
return;
}
System.Threading.Thread.Sleep(interval);
}
}
}
private void backgroundWorker1_ProgressChanged(object sender, ProgressChangedEventArgs e)
{
IplImage image = (IplImage)e.UserState;
pictureBox1.Image = image.ToBitmap();
}
こいつを基本形として手足を加えていくことにする。
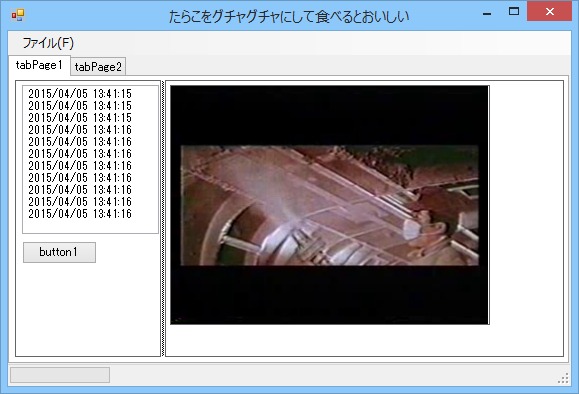 画像03: BackgroundWorkerによる動画再生の実装
画像03: BackgroundWorkerによる動画再生の実装
今回はflvを読み込むテスト。いい感じに読み込めた。
ただし音声は再生されないしMPCと並べてみると僅かではあるが再生速度が遅くなってしまう。
これは各フレーム描画のタイミングをThread.Sleepで調整しているだけなので仕方がない。今回音声は関係ないので無視。
しかし現状では再生ボタンを押したら最初から最後まで再生する以外選択肢がない。
任意の位置からの再生・一時停止・再開・コマ送り・巻き戻し・その他便利機能をくっつけたい。
任意の位置からの再生・巻き戻し
調べても前例が何も出てこなかったのでOpenCvSharpのソースを見てみる。
-
opencvsharp/CvCapture.cs at master · shimat/opencvsharp · GitHub
https://github.com/shimat/opencvsharp/blob/master/src/OpenCvSharp/Src/HighGUI/CvCapture.cs
どうやらcapture.PosMsec、capture.PosFrames、capture.PosAviRatioあたりを使えば良さそう。
以下のように書けば60秒の位置から再生してくれる。
capture.PosMsec = 60 * 1000;
または以下のようにしても同じ結果が得られる。
capture.PosFrames = (int)(capture.Fps * 60);
逆再生はともかく巻き戻しはこいつで何とかなりそう。
一時停止・再開・コマ送り
今のところwhileだけで作っているので動画が終わるまでループが回り続ける(=一時停止できない)。
一時停止したければどこかのタイミングでループを止めなければならない。
一時停止はループが止まれば何でもいいのでBackgroundWorker.CancelAsync()だけでおk。
再開するときには一時停止した位置から再生を開始すればおk。
コマ送りは1回だけcapture.QueryFrame()すればおk。
いずれの操作を行う場合もBackgroundWorker.IsBusyを確認する必要がある。
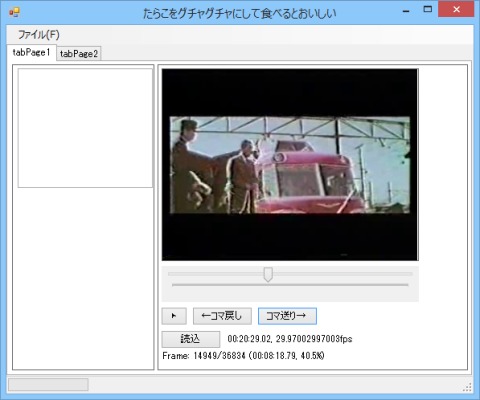 画像04: 動画再生に関する各種機能の実装
画像04: 動画再生に関する各種機能の実装
ここまでの機能の実装結果は上の画像の通り。概ね思い通りに動いている。
複数動画の同期再生
元動画だけでなく標本も動画なので2つの動画を並べて表示できるようにする。
またサンプリングしやすいように同期再生もできるようにゴニョゴニョする。
ただし今回は簡単のために2つの動画のフレームレートが等しいことを仮定する。
この条件を満たしていない場合は標本動画をエンコードし直してから読み込むことにする。
動画上に図形を描画
今回用いる動画は上下左右に黒い余り部分があるので、その部分を学習対象から除外する必要がある。
その範囲の指定を視覚的に解かりやすくするために動画上に四角形を描画する。
また、四角形内に部分的に除外したい領域がある場合はその領域を表す四角形も描画する。
1つ引っ掛かったことがあるのでメモ。
pictureBoxの大きさの指定は枠線も含んだ大きさになっている。
例えば320x240の動画を等倍で表示したい場合、上下左右の枠線各1pxを加算した322x242のpictureBoxが必要になる。
選択領域一致の確認
領域を選択するだけでは領域が一致しているか確認しづらい。
そこで、選択領域を切り出して表示するためのpictureBoxを用意、パラパラ漫画の要領でズレを確認・修正できるようにする。
ここでも1つ引っ掛かったことがあったのでメモ。
Bitmap.CloneでどうしてもOutOfMemoryExceptionが発生してしまう時は引数がどこか間違ってる。
座標が負になるような画像の領域外を指定してるとか、RectangleがRectangleFになってるとか。
VSからは追加情報として「メモリが不足しています。」などと言われるので勘違いして1時間ぐらい時間を溶かしてしまった。
-
C#で、GraphicsのDrawImageメソッドがOutOfMemoryExceptionを出す « プログラミング « コンピューター « デルタンのツイッターではまとめられないことを書くブログ
http://blog.livedoor.jp/deltan12345/archives/52896831.html
訓練の開始・終了フレーム指定
機械学習に用いるフレーム範囲を指定する。
再生速度とフレームレートが同じであることを仮定しているので、フレーム数は同じでなければならない。
UI実装
ここまでに書いたものを全て実装したところ下の画像の様になった。左ペイン下方がパラパラ漫画。
右ペインは左が元動画、右が標本動画。動画上の黄緑の点線が切り取り指定領域。この四角内が機械学習の対象。
「四角内」と言っても左と上の枠線上は含む一方で右と下の枠線上は含まないというややこしい感じになっている。
これは切り取り時のRectangleと四角形描画時のRectangleを共通化しているため起きる現象であり回避が面倒なので放置。
「♪小田和正」の部分を対象から除外するために付けた"除外領域指定機能"は最終的に無用の長物と化してしまった。まあいいや。
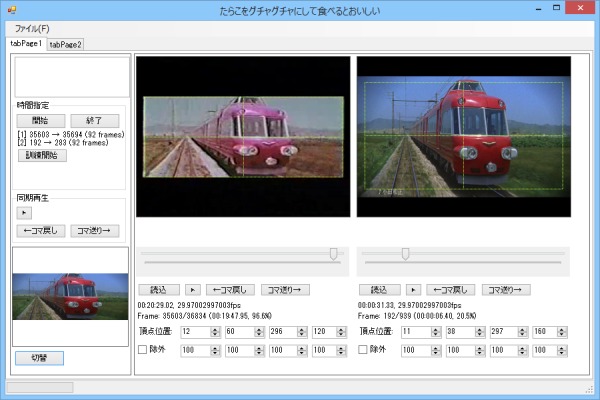 画像05: 動画再生に関する追加機能の実装
画像05: 動画再生に関する追加機能の実装
また、後の為に頂点位置パラメータはファイルに保存・復元できるようにしておく。
これでようやく準備が整った。いよいよ機械学習の開始である。
機械学習による褪色復元
ここからが本題。褪色復元を行う。
とりあえずやってみる
復元と言っても原理は非常に単純で「元動画→標本動画」の色マッピングを行うだけである。
まずは1フレームのみマッピング処理してみる。大きさが296*120=35520なので最大で35520色分のマッピングができる。
きちんと復元できるかどうかは最初の方で出した画像の補正によって確かめる。
 画像06: 1フレームのみのマッピングついて学習した結果
画像06: 1フレームのみのマッピングついて学習した結果
ん?何だか思ったより微妙な結果な気がしないこともないような…。
まあいいや。とりあえず標本増やして精度が増すかどうか見てみることに。今度は30フレーム分の情報を学習させる。
学習にはかなりの時間が費やされる。
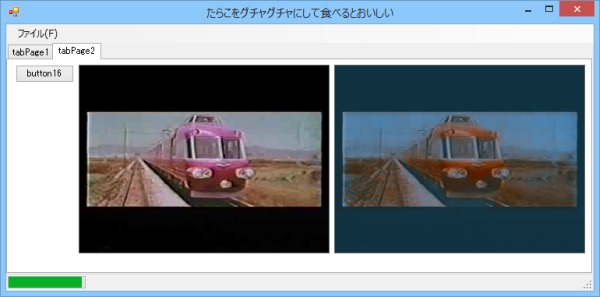 画像07: 30フレームのマッピングついて学習した結果
画像07: 30フレームのマッピングついて学習した結果
駄目じゃん。
悪化してるじゃん。
解像度が高いと(と言っても296x120だが)ノイズやらブレやらの影響を全部飲み込んで変な結果になってしまうのかな?
標本数が多いほど誤差も累積するので標本を多くするほどコントラストが低くなってしまう、ということらしいと勝手に予想。
それならばこれを回避するためには誤差の影響が小さくなるまで情報量を小さくすれば良さそう。
…などと考えて試しに1フレームの情報量を120*60まで落としたが結果はほぼ同じであった。
中間層のニューロン数を調整してみる
ここまではずっとニューロン数を変えずにやってきたが、これを弄れば結果が改善するかもしれない。
噛み砕いて言うと、褪色復元処理は中間層のニューロンがたったの7つで上手く一般化できるほど単純ではないということのようだ。
まずは中間層のニューロン数を7から5へ減らして経過を見てみる。
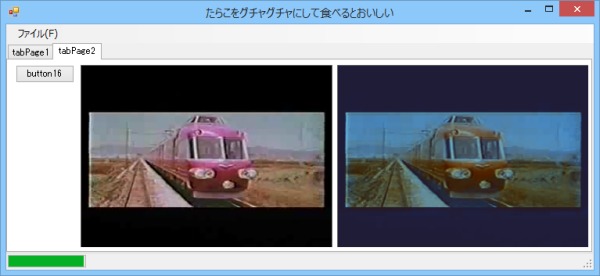 画像08: 中間層のニューロン数を5つにして学習した結果
画像08: 中間層のニューロン数を5つにして学習した結果
うん、汚いね。赤色がさっきよりも青くくすんだ色になったのがお分かりいただけるだろう。
それでは今度は逆にニューロン数を増やしてみる。思い切って32個にしてみたところ以下のように。
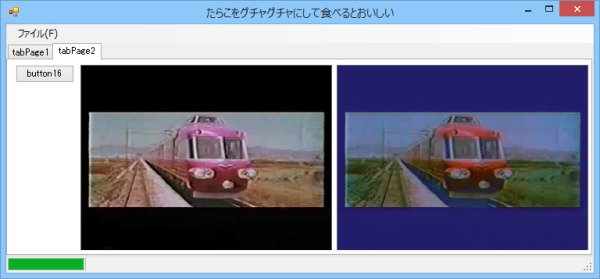 画像09: 中間層のニューロン数を32個にして学習した結果
画像09: 中間層のニューロン数を32個にして学習した結果
いけるじゃん!!!
調子に乗ってニューロン数を一気に増やしてみた。
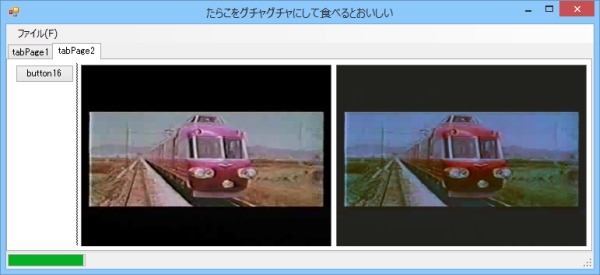 画像10: 中間層のニューロン数を80個にして学習した結果
画像10: 中間層のニューロン数を80個にして学習した結果
ん???イマイチ…でも黒系の表現はしっかりしてきたような。
もしかしたら過学習してしまったのかもしれない。ならばニューロン数はいくつが丁度いいのか。今度はさっきの半分の16個で試す。
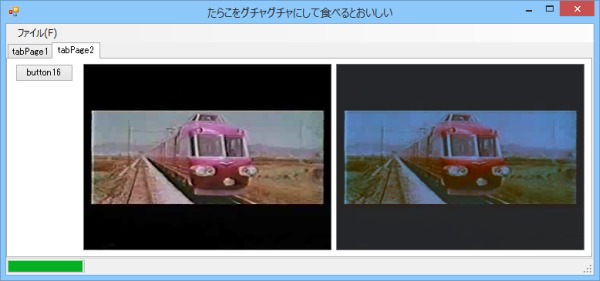 画像11: 中間層のニューロン数を16個にして学習した結果
画像11: 中間層のニューロン数を16個にして学習した結果
16個では足りないみたい。それなら少し増やして45個ならどうだろう。
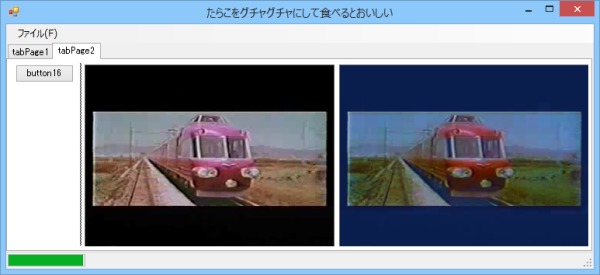 画像12: 中間層のニューロン数を45個にして学習した結果
画像12: 中間層のニューロン数を45個にして学習した結果
うーん…可もなく不可もなく、といったところだろうか。
結局いくつが丁度いいのか分からなかったので、これからは先に学習用データだけ整理して後で一気に読み込めるようにしておく。
ひとまず32個でいいかな?という感じで今は保留。
数秒分の訓練用データを保存してみると9.5MBにもなった。訓練に物凄い時間が掛かる理由が何となく理解できた気がする。
この数秒分のデータ訓練には数分もの時間を要するので、サンプルの量はほどほどにした方が良さそうな気もしてきた。
で、その訓練の結果が以下。
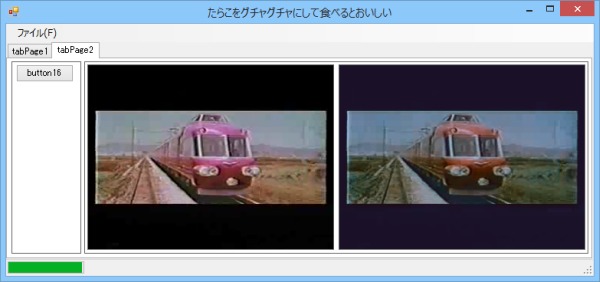 画像13: 訓練の結果
画像13: 訓練の結果
なんか暗くね?と思っているそこの貴方、実は輝度・彩度を少しだけ弄ってやるとこんな感じになるのだ。
これは適当にやっただけだから本当はもっと綺麗にできるはず。輝度+15, 彩度+35あたりでもそこそこ綺麗になる。
 画像14: 訓練の結果(補正後: 明るさ+35, コントラスト+15, 彩度+55)
画像14: 訓練の結果(補正後: 明るさ+35, コントラスト+15, 彩度+55)
実はCMだと4隅が暗かったり色々とあったので正直に訓練すると補正が必要になってしまう。
とはいえ少し補正すればいいだけなのでそれほど手間でもない。
動画の出力
さて、そこそこ補正ができるようになったので動画を出力したい。
出力方法が分からなかったので調べたら以下の通りであった。
-
おちラボ:教育システム研究開発BLOG: C#: OpenCVSharpでビデオファイルを作成する
http://ochi-lab.blogspot.jp/2012/02/c-opencvsharp.html
出力状況は表示できるようにしてみた。ただし明るさ調整などの項目はただの張りぼて。
機能付けようかと思ったけどめんどかったからやめた。どうせAviUtlあたりで修正すればいい話。
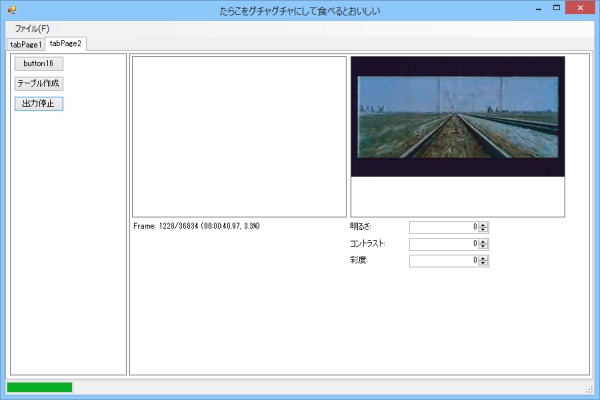 画像15: 動画出力の様子
画像15: 動画出力の様子
320x180、29.97fpsの動画で変換速度は0.25倍くらい。実時間の4倍くらい待つ。ただただ待つ。
結果どんな動画ができたかというと以下の通り。
 画像16: 出力された動画
画像16: 出力された動画
これは中間層のニューロン数32のときの動画出力をAviUtlで補正したものである。
CMにはこの4つの場面・計8秒が入っていたのでこれを標本としたが、結果は微妙と言わざるを得ない。
掲載はしないが他の場面は殆どが酷いものである。綺麗に補正するにはサンプルとニューロン数を増やす必要がありそうだ。
中間ニューロン数の調整
ごく当たり前の話ではあるが、中間層のニューロン数は多ければ多いほど複雑な処理ができる。
ただし、ニューロン数が多くなりすぎると過学習状態となり未知入力に対して汎化できない機械となってしまう。
では一体いくらにすれば丁度いいのか。
訓練データ数が少ない場合に中間層のニューロン数を無駄に多くすると汎化能力を失ってしまう。
逆にニューロン数が少なすぎても駄目。
今回は入力も出力も256^3=16777216通りなので、この入力情報を完全に無損失に表現するには2^16777216個の中間層ユニットが必要。
しかしそれほど大量に用意すると汎化できないし、そもそもそんなに用意できない。
この説明だと、ニューロン数はもっと多くても良さそうだ。
そこで、まずは以下のような画像を用意。個々の画像は元映像から切り出したものである。
 画像17: 比較用見本画像
画像17: 比較用見本画像
この画像の補正結果がニューロン数でどのように変化するのかを見てみることにする。
まず以下が中間ニューロン数32のとき。明るさ・コントラスト・彩度を上げると大分見やすくなるがそのままでは暗い画像。
 画像18: 中間ニューロン数32のときの補正結果
画像18: 中間ニューロン数32のときの補正結果
次に以下が中間ニューロン数80のとき。少々明るくなったようだが全体に赤み掛かっている。
 画像19: 中間ニューロン数80のときの補正結果
画像19: 中間ニューロン数80のときの補正結果
さらに以下が中間ニューロン数256のとき。思い切って増やしたので訓練だけで20分ほど掛かったが…駄目じゃん。過学習っぽい。
 画像20: 中間ニューロン数256のときの補正結果
画像20: 中間ニューロン数256のときの補正結果
それなら少し減らしてみる。以下は中間ニューロン数55のとき。今までで一番マシに見えなくもないが全体的に緑が強すぎる。
 画像21: 中間ニューロン数55のときの補正結果
画像21: 中間ニューロン数55のときの補正結果
ニューロン数に関わらず暗部は全体的に赤みが強く出てしまう傾向にあり、補正が上手くできなかった。
ここまで来て何となく気付いた。標本の場面数が4つではサンプルとして不十分すぎるのではないか?
明るさやコントラストが多様な他の場面を標本とすることでもっと高い精度で補正できるのではないか?
別の標本を用いた訓練
今まで標本にはCMを用いてきたが、冒頭で少し述べたように一部の映像がDVDになっているのでそちらを標本として用意した。
この映像を入手してから気付いたことだが、CMの映像はいくらかの加工がなされたものであり標本には適さないようだ。
周縁部が暗くなっていたり色が濃くなるように補正されていたりといった具合である。
DVDの方を使えば今度は補正後の画像が暗くなったりはしないはずである。
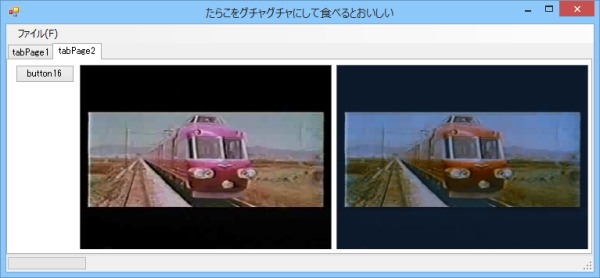
 画像22: CMとDVDの比較
画像22: CMとDVDの比較
また、今度は標本フレーム数が多いので情報を120x60から90x45まで落とす。さらにさらにその中から適当に1/7だけを用いる。
あまりに標本が多いと一気にOpenCVに渡せず面倒なことになるのでこうしてデータを少々削減する。
CMからはどう足掻いても4場面しかサンプリングできなかったが今度は計25カットからサンプリングすることができる。
以前に比べて多様なパターンの標本が手に入ることが期待されるのでもっともらしい補正ができるはずだ。
当然ながらもっともらしいマッピングを求められるのは中間ニューロン数の調整が適当になされている場合のみである。
よって、中間ニューロン数をいくらにすればよいのか試しながら見ていくことにする。
中間ニューロン数を変えての訓練にはとてつもなく時間を要することが容易に想像できるが試さない手はない。
この際なのでリソースと時間をガンガン費やして補正を試みた。中間ニューロン数の順に結果を示す。
▼中間ニューロン数30。訓練時間12分44秒(23:09:02~23:21:46)。
 画像23: 中間ニューロン数30のときの補正結果(DVD標本)
画像23: 中間ニューロン数30のときの補正結果(DVD標本)
▼中間ニューロン数40。訓練時間17分42秒(23:24:53~23:42:35)。
 画像24: 中間ニューロン数40のときの補正結果(DVD標本)
画像24: 中間ニューロン数40のときの補正結果(DVD標本)
▼中間ニューロン数50。訓練時間16分37秒(22:43:56~23:00:33)。
 画像25: 中間ニューロン数50のときの補正結果(DVD標本)
画像25: 中間ニューロン数50のときの補正結果(DVD標本)
▼中間ニューロン数60。訓練時間19分09秒(23:44:50~0:03:59)。
 画像26: 中間ニューロン数60のときの補正結果(DVD標本)
画像26: 中間ニューロン数60のときの補正結果(DVD標本)
▼中間ニューロン数70。訓練時間15分56秒(0:07:20~0:23:16)。
 画像27: 中間ニューロン数70のときの補正結果(DVD標本)
画像27: 中間ニューロン数70のときの補正結果(DVD標本)
▼中間ニューロン数80。訓練時間18分26秒(0:26:03~0:44:29)。
 画像28: 中間ニューロン数80のときの補正結果(DVD標本)
画像28: 中間ニューロン数80のときの補正結果(DVD標本)
▼中間ニューロン数90。訓練時間20分53秒(0:47:36~1:08:29)。
 画像29: 中間ニューロン数90のときの補正結果(DVD標本)
画像29: 中間ニューロン数90のときの補正結果(DVD標本)
▼中間ニューロン数100。訓練時間15分12秒(1:10:24~1:25:36)。
 画像30: 中間ニューロン数100のときの補正結果(DVD標本)
画像30: 中間ニューロン数100のときの補正結果(DVD標本)
終始微妙な結果であった。最後の方は過学習気味だったので今度は30から減らしてみる。
▼中間ニューロン数20。訓練時間11分15秒(1:31:23~1:42:48)。
 画像31: 中間ニューロン数20のときの補正結果(DVD標本)
画像31: 中間ニューロン数20のときの補正結果(DVD標本)
こっちの方がマシじゃん。
何故こんなことになったのか考えてみた。
- 元動画のブレが考慮されていない
- 標本が場面ごとに量的に偏っている
- 標本の品質が場面ごとに異なる
- プログラムのミス
くらいしか頭に浮かばなかったがとりあえず以下のようにしてみた。
- 標本動画を全て使うのはやめて一部のフレームを抜き出す形にしてみる
- 各場面から同じ数だけのフレームを抽出する
- 使用する標本場面数を減らす
- 処理部をちょっと前のプログラムに戻す
さて、どうなるか。
とりあえず、3つの場面から計33フレームを抜き出して中間ニューロン数60で訓練してみる。
訓練時間0分27秒。
 画像32: 少ない標本を元にしたマッピング(DVD標本)
画像32: 少ない標本を元にしたマッピング(DVD標本)
案外こっちの方がいけるじゃん。
もうどうしたらいいのか訳わからなくなってきた。
まとめみたいな何か
よりよい結果を得るためには何をすれば良さそうか。
- 標本はブレ方が元動画と完全に同じになるように補正するかフレームごとに切り取り範囲を設定する
- OpenCVで特徴点抽出すればできそう?
- FFmpegの手ぶれ補正フィルタvid.stab使えばできそう?
- 標本は元動画に対して量的に偏りがないように各場面から適切なフレーム数を抽出する
- もしくは入力データに重み付けを行う
- 可能ならば色マッピングは動画全体で共有しないでフレームごと又は場面ごとに設定する
- 標本動画はもしかしたら場面ごとに異なる補正が施された後かもしれない(とうか結構な確率でそのように処理している)
- 新岐阜駅に帰ってくる場面は夕方なので本来もっと赤みがかかった画になっているがDVDでは綺麗に補正されている
- 現状で一番現実的な打開策、ただし面倒なのに変わりはない
- 殆どの場面には標本が存在しないので適切なマッピングを選択しなければならない
- 「色→色」のマッピングでは不十分かもしれない
- 周囲の領域の色・画像全体の色味・場面全体の色味と何らかの相関関係があるかも?
- 画面上の位置と何らかの相関があるかも?
- そもそも元動画の劣化状態がフレーム(実際にはフィルムのどの辺か)ごとにバラバラなら修復不可能
- 1フレームずつ確認しながら補正すればできなくはない
- 業者にでも頼んだ方がいい
そういうことなので、いつかリベンジしたい。
付録
プログラムを書いたりページ作成したりの途中に参照したページ。
-
SyntaxHighlighter
http://alexgorbatchev.com/SyntaxHighlighter/ -
16:9の整数倍解像度一覧 | Lunatilia
https://lunatilia.wordpress.com/knowledge/resolutions-ar-16to9/
あとメモ。
- 「メモリが不足しています」などといわれた時には本当にメモリが不足しているとは限らない。ここまでに以下の2通りを経験した。
- 本当にメモリが不足している(バイナリフォーマットした1GBくらのデータを読み込んだらメモリ不足になった)
- 引数が不正な値である(BitmapのコンストラクタにXやYが負のRectangleを渡すと「メモリが不足しています」)